Trust challenge about prediction of classifier
Speaker: Marco Tulio Ribeiro
Despite widespread adoption, machine learning models remain mostly black boxes. Understanding the reasons behind predictions is, however, quite important in assessing trust, which is fundamental if one plans to take action based on a prediction, or when choosing whether to deploy a new model. Such understanding also provides insights into the model, which can be used to transform an untrustworthy model or prediction into a trustworthy one. In this work, we propose LIME, a novel explanation technique that explains the predictions of any classifier in an interpretable and faithful manner, by learning an interpretable model locally around the prediction. We also propose a method to explain models by presenting representative individual predictions and their explanations in a non-redundant way, framing the task as a submodular optimization problem. We demonstrate the flexibility of these methods by explaining different models for text (e.g. random forests) and image classification (e.g. neural networks). We show the utility of explanations via novel experiments, both simulated and with human subjects, on various scenarios that require trust: deciding if one should trust a prediction, choosing between models, improving an untrustworthy classifier, and identifying why a classifier should not be trusted.
To gain trust:
- Interpretable models (conclusion + reason)
- Accuracy
- A/B Test
Sparse linaire regression
Mechanical Turker
LIME: 6 factors to explain the decision
Apache SAMOA
Speaker: Albert Bifet, Telecom-Paristech
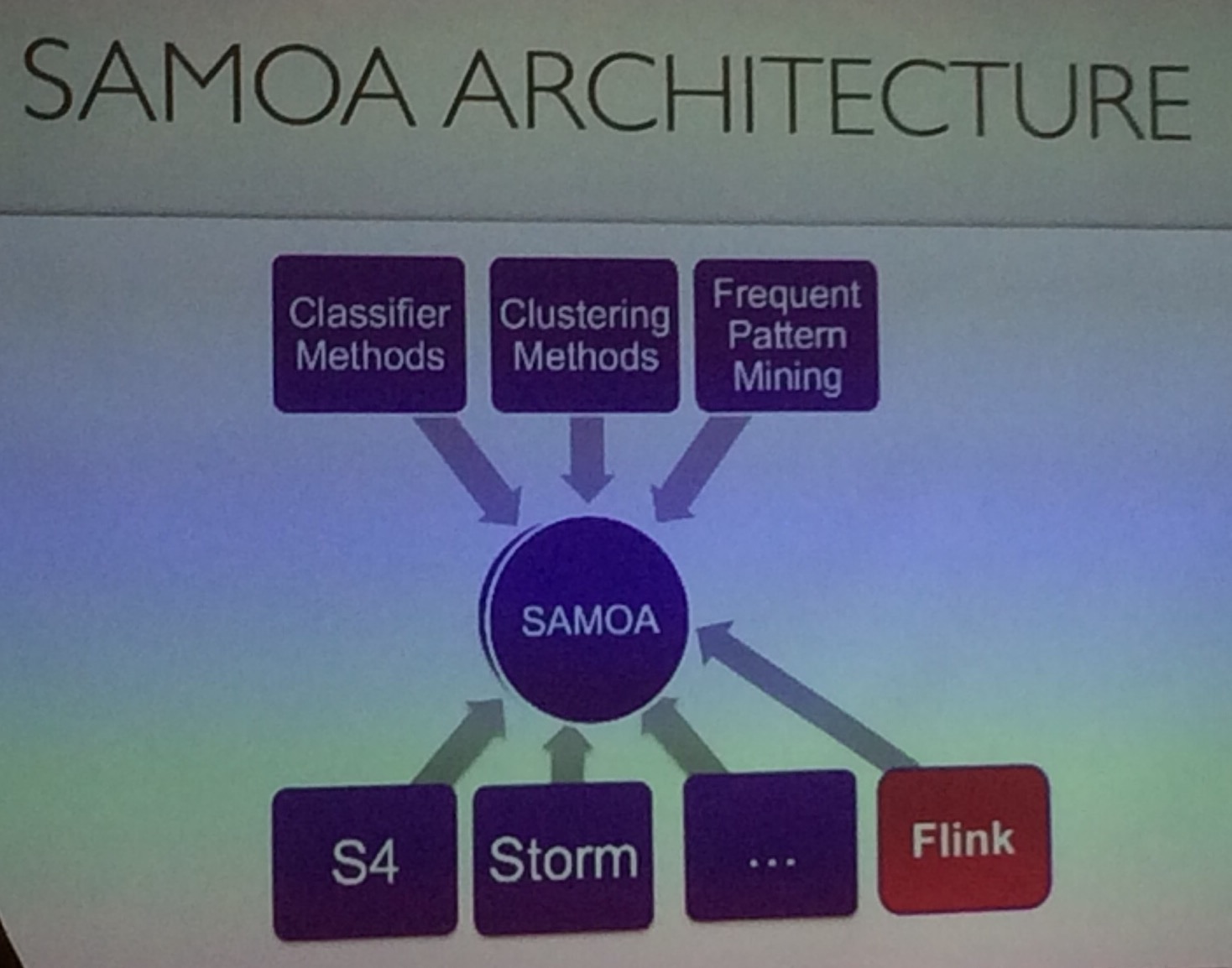
An open-source platform for mining big data streams with Apache Flink, Storm and Samza. Real time analytics is becoming the fastest and most efficient way to obtain useful knowledge from what is happening now, allowing organizations to react quickly when problems appear or to detect new trends helping to improve their performance. Apache SAMOA includes algorithms for the most common machine learning tasks such as classification and clustering. It provides a pluggable architecture that allows it to run on Apache Flink, but also with other several distributed stream processing engines such as Storm and Samza.
Real-Time Analytics => Streaming model
Need to retrain model with new data
MOA (Massive Online Analysis)
Vertical Parallelism
sequential evaluation for online learning
GAN (Generative Adversarial Networks)
Speaker: Julien Launay
When modeling transfers through a medium in civil engineering, knowing the precise influence of cracks is often complicated, doubly so since the transfer and fracture problems are often heavily linked. I will present a new way to generate “fake” cracking patterns using GANs, and will then expand on how such novel techniques can be used to learn more about fracture mechanics.
Visualization convolution filters
Manual labelling Service
FouleFactory 50000 fouleurs (students, retired, enployee)
Here is the official reference blog
Chinese version reflective writing:
LIME 项目用来跟受众更好地解释机器学习的决策,适合作为工具在会议中说服公司上层。一个例子,怎样让机器来识别图片中的哈士奇,和狼。LIME通常会给出六大理由,其中理由之一是,图片中有雪时,就判断是哈士奇。
Apache SAMOA 用来对接实时数据流和各种机器学习算法,实现高效的online learning.
GAN(Generative Adversarial Networks) 通过产生器和判别器生成可信度高的含label图像训练集,用在计算机视觉领域。
还有一个来自meetup赞助商的广告,因为内容比较有意思,所以也写进来了。鉴于监督学习在工业界需要大量的人力labelling,这家公司就搭建了一个网络平台,广大闲人们可以通过零散的labelling work赚取外快,业界又可以在短期内迅速获得人力标记的高质量训练集。